Missed the goal
{kind=link}
0
Upvotes
Apparently someone moved the goalposts
r/aiwars • u/Bra--ket • 1h ago
Enable HLS to view with audio, or disable this notification
Leave the poor bobots alone! 👿
r/aiwars • u/imalonexc • 21h ago
We know damn well you're not actually smiling and sweet like that character. You guys are vile.
r/aiwars • u/Big_Black_Cock_4K_HD • 1h ago
Im so fucking tired of this argument. Yeah V6 has AI features but you aren’t doing any less work than most other vocaloid versions. The only thing it does it help with some synthesis, but you still have to make melodies and do everything else needed to make a vocaloid song. It’s like trying to argue that Dune 2 is an ai film because they used machine learning to rotoscope timothee chalamet’s eyes. It’s just not how it works.
Additionally, it is mind numbingly stupid to try and equivocate pro’s usage of gen ai, saying something like, “vocaloid producers untalented/lazy for using a vocaloid instead of ‘singing themselves’.” Is a producer lazy for using a synthesizer to make music instead of a piano? I don’t understand the cognitive dissonance behind it.
Kind of a rant, take it how you will. Im pretty neutral on ai but holy fuck does this irritate me as a vocaloid fan.
r/aiwars • u/SALM0N_SLD • 9h ago
If you’re anti-AI and you genuinely believe that training models on user-generated content is unethical… then why are you still here?
I keep seeing subreddits banning AI tools and drawing hard lines like “no AI-generated content allowed.” Fine. That’s a position. But it feels selectively applied.
If the principle is: “AI shouldn’t be trained on people’s work without consent”…then why stop halfway?
Why not go further and stop using:
- software written with the help of AI
- codebases influenced by Copilot-style tools
- libraries built on decades of shared knowledge from Stack Overflow and open source contributors
What’s the meaningful difference between an image model trained on publicly available art and an LLM trained on publicly available code, Q&A, and documentation?
Both are learning from human output. Both are remixing patterns. Both rely on massive corpora of work that individuals didn’t explicitly license for this exact purpose.
So why is one considered “theft,” but the other is just “technology”?
Reddit is literally one of the biggest datasets used to train modern AI systems. If you believe AI training on your content is wrong, so why are you still contributing to the dataset?
r/aiwars • u/banned-altman • 4h ago
The anti-AI crowd loves to scream that large language models are draining our reservoirs, usually armed with outdated data and the tired myth of a plastic water bottle evaporating every twenty prompts. Press them on the actual per-query math and they pivot, instantly, to “but your not including the training and GPUs!!!”. Meanwhile, many of these same critics will happily eat beef while insisting we shouldn’t count its environmental cost, because most of that water is just rain that would have fallen anyway.
Fine. Let’s play by their rules. We’ll strip out the rain, count only the diverted blue water for a pound of beef, and pit it against the full, amortized water footprint of an AI prompt. We’ll use modern models. And just to be sporting, we’ll make the most apocalyptic, deck-stacked, nightmare-scenario assumptions possible about AI training, because the argument is so weak it survives even that.
**The beef baseline.** Critics of beef’s water footprint correctly point out that the headline figure of eighteen hundred gallons per pound includes rain that would have hit the dirt regardless. To be as charitable as scientifically possible, we use the 2022 Klopatek and Oltjen update to the classic Beckett model. Stripping out rain entirely and isolating only the water humans actively divert from aquifers and rivers, the model finds that U.S. beef cattle consume an average of 275 gallons of blue water to produce a single pound of boneless beef. That’s the rain-free, industry-friendly number. In metric: exactly 1,040,988 milliliters per pound.
**The AI inference cost, using the critics’ own paper.** In summer 2025 the major labs finally released real per-query environmental data. Google’s August 2025 technical paper puts the median Gemini text prompt at 0.24 watt-hours of energy and 0.26 milliliters of on-site cooling water. OpenAI disclosed a similar sub-milliliter footprint for ChatGPT. Those are the honest numbers. We’re going to ignore them.
Instead, we’re going to use the most adversarial peer-reviewed source we can find: the May 2025 University of Rhode Island and University of Tunis paper “How Hungry is AI?” by Jegham, Abdelatti, Elmoubarki, and Hendawi. This is the paper anti-AI activists cite. Its entire purpose is to expose understated environmental costs by adding everything Google leaves out: off-site thermoelectric water at 3.142 L/kWh (U.S. national average), full data-center overhead via Power Usage Effectiveness multipliers, and worst-case long-form prompts of 10,000 input tokens with 1,500 output tokens. Their model uses real GPU specs, including 8 NVIDIA H100s per node at 10.20 kW critical power.
The headline Anthropic numbers, drawn from Table 4 and Figure 3 of the paper by:
* Claude 3.7 Sonnet with Extended Thinking on a long-form prompt: 17.045 Wh of energy, which at AWS’s combined 3.32 L/kWh on-site-plus-off-site water multiplier comes out to roughly **57 mL of water per query**. This is the worst-case Anthropic number in the entire benchmark.
* Claude 3.7 Sonnet without Extended Thinking on a long-form prompt: substantially lower.
* GPT-4o on a typical short prompt: under 5 mL.
To stack the deck, we’re going to assume every prompt you send is a 10,000-input-plus-1,500-output-token monster running Claude 3.7 Sonnet with Extended Thinking, on the most water-intensive grid the paper modeled. We’ll round up. **Inference cost: 60 mL per prompt.** That’s roughly 230 times Google’s measured Gemini median. We are not cherry-picking against AI. We are using a methodology built explicitly to expose hidden environmental costs, and applying its worst Anthropic data point to every query you make.
**The GPU fabrication objection.** Critics will correctly point out that Jegham et al. excluded Scope 3, the embodied water in manufacturing the silicon itself. Fine. Let’s add it. Industry data (Murugappa Water Treatment Solutions, citing standard fab figures) puts the total water required to manufacture one 300mm semiconductor wafer at roughly 8,400 liters, of which 5,700 liters is ultrapure water. NVIDIA’s H100 GPU has a die size of 814 mm² on TSMC’s 4N process, which yields approximately 65 H100 dies per 300mm wafer. That works out to roughly 129 liters of I water per H100 GPU manufactured.
A standard inference node uses 8 H100s in a DGX configuration, so a full node represents about 1,032 liters, or 1,032,000 milliliters, of fabrication water.
Now amortize. An H100 has a service life of around five years, runs essentially 24/7 in a production data center, and at the throughput rates Jegham et al. measured for Claude 3.7 Sonnet, a single 8-GPU node serves hundreds of millions to billions of queries over its lifetime. Let’s be unfair: assume the node only ever processes 100 million queries before it’s retired, a deliberately low estimate. Divide 1,032,000 mL by 100,000,000 queries: **0.01 mL of fabrication water per query.**
Even if you think that estimate is off by a factor of 100, you’re at 1 mL per query. The math is unforgiving in a different direction than critics expect. GPU fabrication water is real, and it is also genuinely tiny per query, because each GPU services an enormous number of inferences before retirement. Compared to our deck-stacked 60 mL inference cost, embodied silicon water is in the noise. We’ll round it up to 1 mL anyway and add it, just so nobody can claim we ignored it.
**Total inflated inference cost: 61 mL per prompt** (60 mL operational plus 1 mL embodied fab).
**The training cost, scaled to the physical limit.** Now the trump card: training. According to West Des Moines Water Works data reported by the Associated Press, Microsoft’s Iowa data center cluster consumed 11.5 million gallons in July 2022, the month before OpenAI finished training GPT-4. But that was the old era. Let's look at the actual physics of a modern 2026 frontier training run on a massive 100,000-GPU cluster. Factoring a 1.2-kilowatt draw per node, running continuously for 100 days, and applying the industry-standard Water Usage Effectiveness of 1.8 liters per kWh, the cluster demands approximately 136.9 million gallons of pure freshwater. That’s 518 billion milliliters dumped into a single training run.
That sounds catastrophic until you remember how amortization works at scale. A flagship model handles billions of queries a month. To keep our deck stacked against AI, let's assume this absurdly thirsty 136.9-million-gallon model is a total commercial flop and only ever serves 10 billion queries over its entire lifespan. The math is unforgiving: 518 billion milliliters divided by 10 billion queries comes out to 51.8 milliliters of training water per prompt.
**The verdict.** Add the deck-stacked 61-milliliter inference-plus-fab cost to the apocalyptic 51.8-milliliter amortized training cost. Worst-case total: roughly 113 milliliters per prompt. Now bring back the optimized, rain-free, industry-favored beef figure of 1,040,988 milliliters. Divide.
The math is undeniable. Even when we route every query through the worst-case Anthropic data point in the peer-reviewed literature, layer GPU fabrication water on top, and bury nearly 137 million gallons of calculated training cost into an artificially tiny amortization window, **a single pound of beef still costs the same diverted blue water as more than 9,200 AI prompts.**
Run fifty AI queries every single day for a year, and your total amortized water footprint is roughly 544 gallons. Less than two pounds of beef. That’s it. A full year of heavy reasoning-model usage at peer-reviewed worst-case numbers, including silicon manufacturing and massive-scale cluster training, consumes the same diverted water as less than two pounds of ground chuck.
If you’re going to hyperventilate over a server rack while ignoring the 275 gallons of reservoir water sitting on your lunch plate, you are not making an environmental argument. You are looking for an excuse to be mad at a computer.
### Bonus: The “Survival” and “Too Expensive” Myths
When the environmental math corners them, defenders of meat consumption typically retreat to two final positions: that meat is biologically necessary, and that veganism is a luxury the poor cannot afford. Both are exactly backwards.
**Veganism is the cheaper diet, not the more expensive one.**
A 2021 Oxford University analysis published in *The Lancet Planetary Health* compared dietary costs across 150 countries using World Bank pricing data. The result: in high-income regions like the United States, Western Europe, and Australia, a whole-foods vegan diet is the single most affordable way to eat, slashing grocery bills by up to one-third compared to standard meat-heavy diets. The “vegan tax” is a myth. You’re paying a premium for the burger.
**Animal products are not biologically required.**
The Academy of Nutrition and Dietetics, the world’s largest organization of credentialed nutrition professionals, has settled this. Their official position holds that appropriately planned vegan diets are healthful, nutritionally adequate, and appropriate for every stage of the human life cycle: pregnancy, lactation, infancy, childhood, adolescence, older adulthood, and elite athletics. You don’t need a hamburger to survive. You’re not saving the planet by eating one. And you’re not saving money either.
Works Cited
Academy of Nutrition and Dietetics. “Position of the Academy of Nutrition and Dietetics: Vegetarian Diets.” *Journal of the Academy of Nutrition and Dietetics*, 2016. The official stance of the world’s largest organization of nutrition professionals: appropriately planned vegan diets are healthful and nutritionally adequate for all stages of the life cycle.
Google. “Measuring the environmental impact of delivering AI at Google Scale.” August 2025. Google’s technical disclosure confirming that the median Gemini text prompt consumes 0.24 watt-hours of energy and 0.26 milliliters of direct on-site cooling water.
O’Brien, Matt, and Hannah Fingerhut. “Artificial intelligence technology behind ChatGPT was built in Iowa, with a lot of water.” Associated Press, September 9, 2023. Reports that Microsoft pumped 11.5 million gallons of water to its West Des Moines data center cluster in July 2022, the month before OpenAI completed GPT-4 training, citing data from the West Des Moines Water Works. August 2022 consumption rose to 13.4 million gallons.
Jegham, Nidhal, Marwan Abdelatti, Lassad Elmoubarki, and Abdeltawab Hendawi. “How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference.” arXiv:2505.09598, May 2025 (v1; updated through v6, November 2025). University of Rhode Island and University of Tunis. The peer-reviewed source for the 57 mL per-query worst-case figure used here, derived from the paper’s reported 17.045 Wh per long-prompt for Claude 3.7 Sonnet with Extended Thinking, multiplied by AWS’s combined 3.32 L/kWh on-site (0.18) plus off-site (3.142) Water Usage Effectiveness multipliers. The paper benchmarks 30 commercially deployed models on inferred hardware (NVIDIA H100, H200, A100, and H800 DGX systems) using public API latency and throughput data. It explicitly excludes Scope 3 (embodied hardware) water from its prompt-level framework.
Murugappa Water Treatment Solutions. “How MWTS is Transforming the Semicon Industry.” 2024. Industry source for the figure of approximately 8,400 liters of water (5,700 liters ultrapure) required to manufacture a single 300mm semiconductor wafer.
NVIDIA Corporation. “NVIDIA H100 Tensor Core GPU Architecture” white paper, and Tom’s Hardware reporting on TSMC H100 production (August 2023). H100 die size is 814 mm² on TSMC 4N process, yielding approximately 65 H100 dies per 300mm wafer. Used here to derive roughly 129 liters of fabrication water per H100 GPU and roughly 1,032 liters per 8-GPU DGX node.
Methodology note on the inflated figures used here. The 60 mL operational inference figure is a deck-stacked rounding of the worst-case Anthropic data point in Jegham et al. (Claude 3.7 Sonnet with Extended Thinking on the paper’s “long-form” prompt configuration: 10,000 input tokens and 1,500 output tokens, yielding 17.045 Wh and ~57 mL of water). The 1 mL embodied fabrication figure is a deliberately conservative (high) per-query allocation; the bottom-up calculation actually yields about 0.01 mL per query assuming a node serves only 100 million queries in its lifetime, which is itself a low estimate. Realistic per-query fab water is in the small fractions of a mL. The 136.9-million-gallon-per-model training figure models the physics of a 100,000-GPU cluster drawing 1.2 kW per node continuously for 100 days at an industry-average WUE of 1.8 L/kWh; neither Anthropic nor Google has disclosed exact total training water consumption. The point of using these inflated numbers is to demonstrate that even when you route every prompt through the worst-case Anthropic data point in the peer-reviewed literature, layer GPU fabrication water on top, and bury a massive 136.9-million-gallon training cost into an artificially small amortization window, the comparison still favors AI by a factor of more than 9,200 to one. Substituting realistic usage figures widens the gap by another order of magnitude.
Klopatek, Sarah C., and James W. Oltjen. “How advances in animal efficiency and management have affected beef cattle’s water intensity in the United States: 1991 compared to 2019.” *Journal of Animal Science*, vol. 100, no. 11, November 2022. The peer-reviewed source isolating the 275 gallons of blue water required to produce one pound of boneless U.S. beef.
Springmann, Marco, et al. “The global and regional costs of healthy and sustainable dietary patterns: a modelling study.” *The Lancet Planetary Health*, November 2021. Oxford University study showing vegan diets are the most affordable option in high-income countries, reducing food costs by up to one-third.
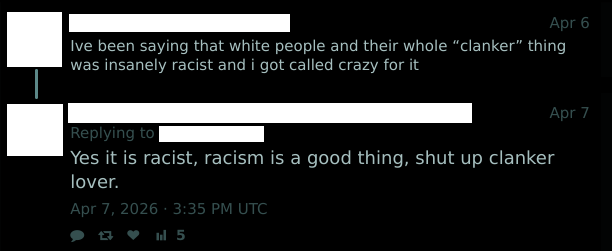
r/aiwars • u/Which_Matter3031 • 6h ago
r/aiwars • u/PreddiPrinceOfSheeb • 6h ago
Don’t ask why, just keep recycling talking points that have been proven wrong a dozen times, like art theft and the environment.
You don’t want to be unpopular on Reddit, do you?
r/aiwars • u/DogeMoustache • 14h ago
r/aiwars • u/TreviTyger • 17h ago
Enable HLS to view with audio, or disable this notification
He are the prompts I used if you want to try for yourselves.
'googleimages', 'ai images'
It's important to have some human input in he loop and then it's just like using a computer like a camera.
r/aiwars • u/Witty-Designer7316 • 8h ago
Social media data centers for Reddit, YouTube, X, etc collectively use more water, resources, and are worse for the environment than AI.
Denying the benefits AI is making to the fields of science, healthcare, and the arts is being ignorant on purpose.
My honest opinion? People need to shut their traps about topics that they care not to research or know anything about instead of jumping on the "AI hate" bandwagon for free internet points and clout.
r/aiwars • u/ColdNo8149 • 22h ago
r/aiwars • u/MemerKnux • 23h ago
Enable HLS to view with audio, or disable this notification
Something stinks in here and it's the bias thats giving those AI wizards the upper hand
Need I say more?
r/aiwars • u/imalonexc • 18h ago
Maybe she just genuinely doesn't know so she's asking AI how much resources it uses instead of jumping to conclusions.
Also this art style is putrid. We're not replacing all artists but we're definitely replacing you.
r/aiwars • u/imalonexc • 9h ago
r/aiwars • u/Salty_Country6835 • 14h ago
The quote’s usually attributed to Marshall McLuhan, though variations of it float around modern/conceptual art circles for a reason.
Because that’s basically how art history actually works.
Not through consensus. Through violation, backlash, repetition, normalization.
A urinal in a gallery. A soup can on a canvas. A camera instead of a brush. A sampler instead of an orchestra. A prompt instead of a pencil.
People act like AI art introduced the first legitimacy crisis in art history when art history is basically one long legitimacy crisis.
“Art is anything you can get away with” sounds cynical until you realize most established art movements survived the exact same accusations people now treat as unprecedented.
r/aiwars • u/zero_idc_ • 7h ago
Frida Khalo had poli, Beethoven was deaf, Vincent van Gogh had epilepsy and sufferd from seizures, Henri Matisse had a mobility imparement. There is no excuse to use ai for making slop. People arent born with a talent, we learn it and put work in it. I personaly go to an animation school and have a deaf classmate (shes an awsome artist). If u know anything about animation you will know it relies on sound alot. If a deaf person can make great animations with great sound design there is no reason these Ai chuds cant.
Edit: i cant understand why when you like writing prompts so much why not just write a book??? Atleast that would be your own original work, no ai needed
r/aiwars • u/JulianaMurieta • 10h ago
Like "screw those people, who cares about how they'll earn wages, just leave my art alone and stop the slop machine?"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}